Summary (Bio)
I have designed and developed a 100 million page web crawler, recommender systems, a program for detecting "spikes" and related queries in search engine logs and a text miner for definitions from web pages.
I have previously worked for Funnelback, a search technology company with blue chip clients like Skype, Rolls Royce and Cambridge University. Prior to that I was a Research Engineer at Australia's national research agency, the CSIRO.
Portfolio
All of the systems or features shown in this portfolio were self-initiated, designed and implemented by myself, unless otherwise stated. The back-end systems were implemented in Java, while the front-ends were done using JavaScript.
Event Mining
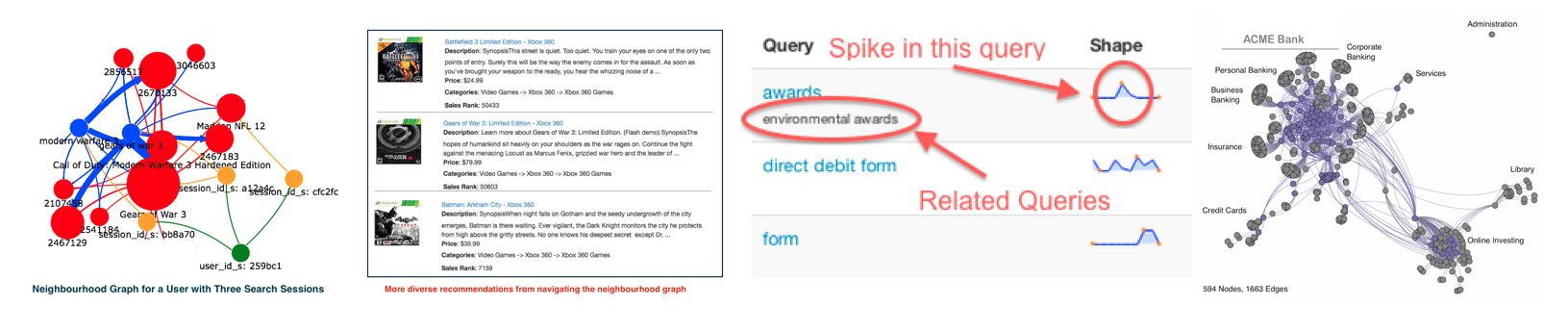
I designed and developed the EventMiner system for mining relationships from "event" logs for Lucidworks in California. The program generates a co-occurrence matrix from the raw event logs and then produces a graph from the matrix which encodes the relationships between users, sessions, queries and documents. The graph is encoded and stored in the Solr search engine, with a full-featured graph API layer also being provided.
The service can navigate the "neighbourhood graph" for an input item:
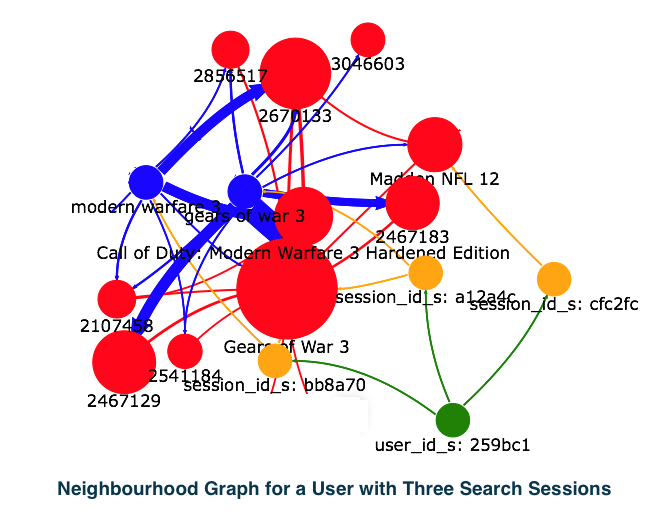
to generate more diverse and high-quality recommendations:
Query Spikes and Related Queries
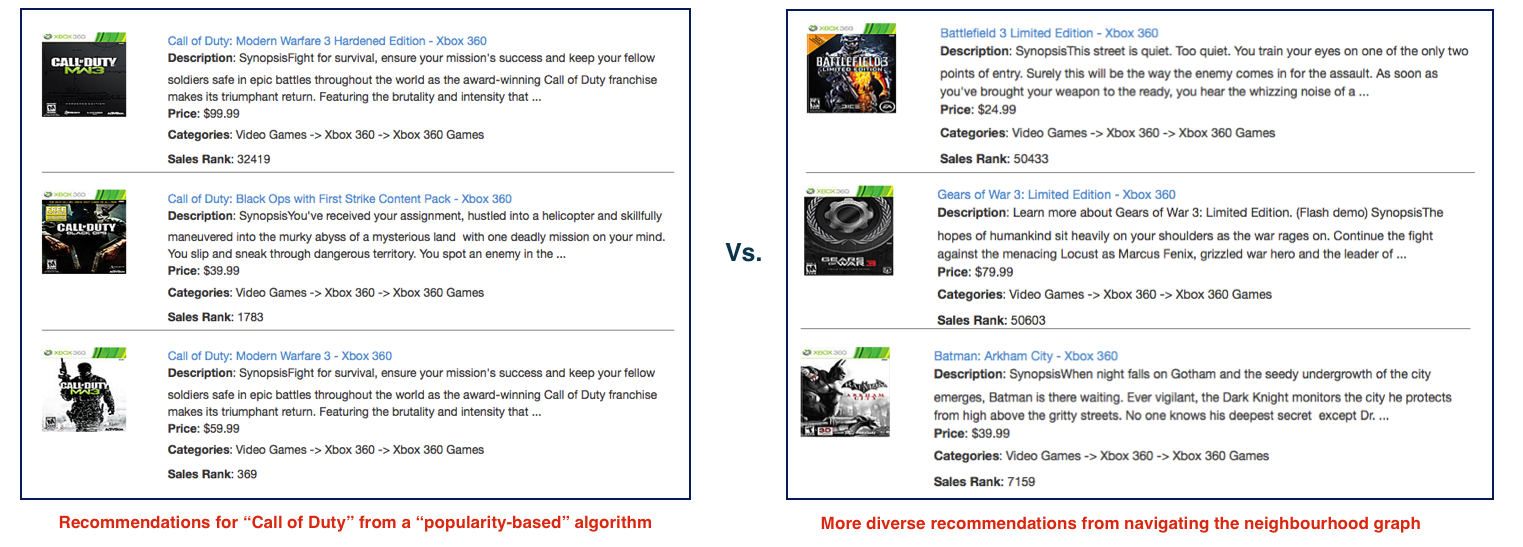
I was the original designer of the Funnelback "Pattern Analyser" system. This can detect spikes in the time series query log data, where these spikes are usually caused by some external event (e.g. a news story). I also designed and implemented a system to automatically detect related queries, based on their click patterns. This can be used to group queries which have no terms in common but have the same semantics.
Recommender Systems
Example of recommended "similar items" overlaid over a StackOverflow question:
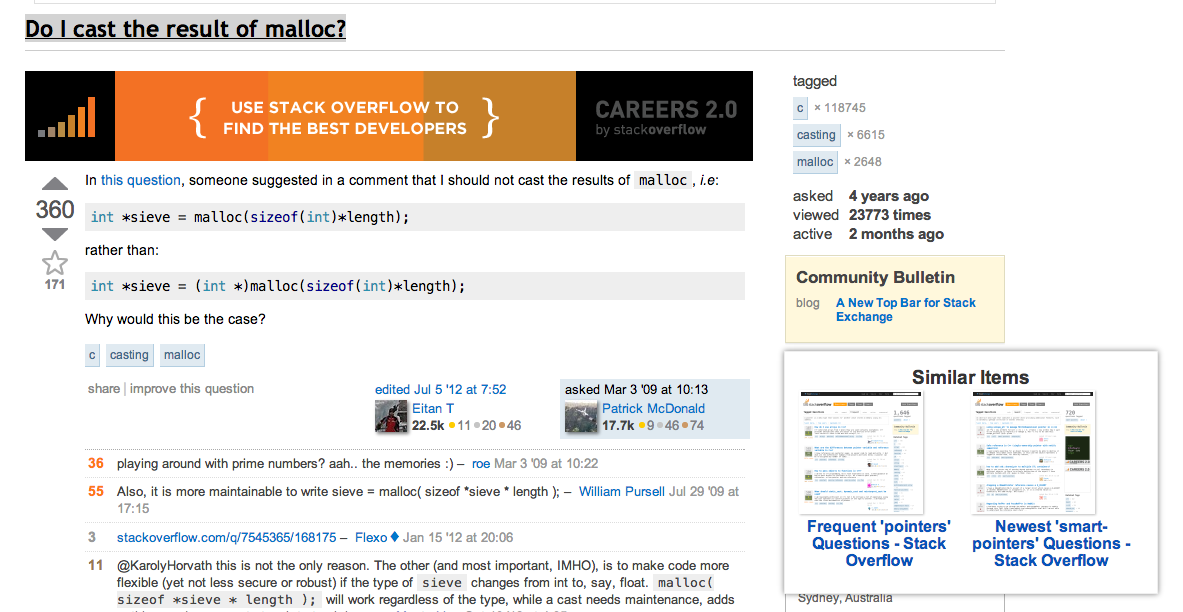
I designed and implemented a recommender algorithm for Funnelback which combines information from multiple sources, such as "co-clicks", "related clicks", "related results" etc.
Web Crawling and Graph Analysis
Example visualization of a web crawl:
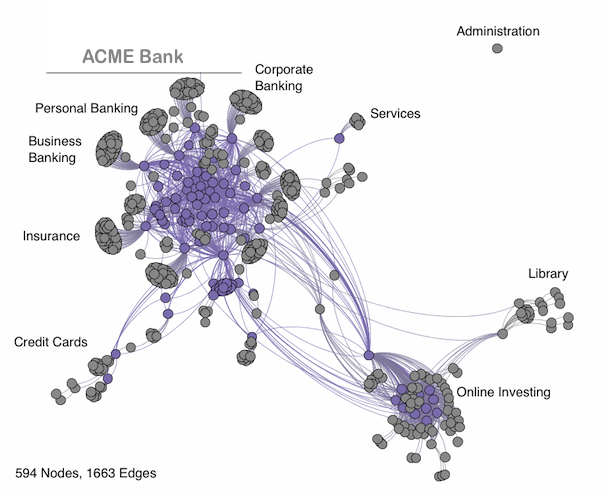
I was the original designer and developer of the Funnelback web crawler, which was designed to minimise resource usage (memory, storage etc.) while crawling 100s of millions of web pages. This software has been in continuous use in hosted and installed sites for over 15 years. I have also done work on analysing crawl link graphs and how "annotations" like queries, clicks and anchortext can be used to enrich the dataset for other applications (including Analytics and Data Mining).
Text Mining
Example of extraction of definitions from text:

I am the creator of a text mining system which uses syntactic patterns to extract definitions for phrases and acronyms. When those terms are used as a query the definition can be displayed at the top of the search results, with a link back to the page that contained the original definition.
Key Skills
- Information Retrieval & Search
- Data Mining
- Analytics
- Distributed Systems
- NoSQL
- Relational Databases
- API Design
- Project Management
- Java
- Python
- JavaScript
- Solr and Elasticsearch
- Spring, Spring Boot
- Vue.js
- Automated Testing
Education
- M.Sc. in Information Retrieval, Dublin City University (1996 - 1998)
- B.Sc. in Computer Applications (1st class honours), DCU (1992 - 1996)
Contact
- Email: francis.crimmins @ gmail.com
- Twitter: https://twitter.com/franciscrimmins
- LinkedIn: https://www.linkedin.com/in/franciscrimmins
- GitHub: http://franciscrimmins.github.io/
Disclaimer
This is a personal site and does not necessarily reflect the views or opinions of any of my previous employers or organisations I have done contracted development for. Details on example systems shown above refer to publicly available information from the official documentation sites for companies such as Lucidworks and Funnelback.